
브루트포스란 완전 탐색 알고리즘으로, 모든 경우의 수를 탐색해서 결과값을 도출하는 알고리즘이다.
모든 경우를 탐색하기 때문에 시간 복잡도가 효율적이지 않지만 코드가 직관적이라는 특징이 있다.
브루트 포스 알고리즘은 일반적으로 O(n), O(n²), O(n³) 등의 시간이 걸리며, 입력 크기가 커지면 성능이 급격히 나빠진다.
이 문제의 경우 3개의 카드를 고르는 상황이라 O(n³)의 시간이 소요된다.
1차 코드
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int count = scanner.nextInt();
int maxNum = scanner.nextInt();
int[] nums = new int[count];
int maxSum = 0;
for (int i = 0; i < count; i++) {
int num = scanner.nextInt();
nums[i] = num;
}
for (int i = 0; i < nums.length; i++) {
for (int j = 0; j < nums.length; j++) {
if(nums[i] == nums[j]){
continue;
}
for (int k = 0; k < nums.length; k++) {
if (nums[j] == nums[k] || nums[i] == nums[k]){
continue;
}
if(nums[i] + nums[j] + nums[k] > maxSum && nums[i] + nums[j] + nums[k] <= maxNum){
maxSum = nums[i] + nums[j] + nums[k];
}
}
}
}
System.out.println(maxSum);
}
}
1. 반복문으로 count 만큼의 값을 입력받는다.
2. 3개의 중첩된 반복문으로 각 카드에 접근하여 총합은 계산한다.
2-1. 만약 카드가 중복인 경우 continue
2-2. 조건문으로 카드의 총합이 입력받은 maxNum보다 작거나 같은 값을 maxSum에 저장한다.
이 코드는 정상적으로 동작하지만, 다른 분이 짠 코드를 보다가 각 반복문의 초기값을 0이 아닌, 이전 반복문의 초기값+1로 설정한 것을 보고 따라서 개선해봤다.
예를 들어 첫 번째 반복문이 i = 0으로 시작한다면, 그 다음 중첩된 반복문은 j = i + 1로 지정하는 것이다.
이렇게 하면 각 카드가 중복될 일이 없기 때문에, 조건문을 넣지 않아도 된다.
2차 코드
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int count = scanner.nextInt();
int maxNum = scanner.nextInt();
int[] nums = new int[count];
int maxSum = 0;
for (int i = 0; i < count; i++) {
int num = scanner.nextInt();
nums[i] = num;
}
for (int i = 0; i < nums.length; i++) {
for (int j = i + 1; j < nums.length; j++) {
for (int k = j + 1; k < nums.length; k++) {
if(nums[i] + nums[j] + nums[k] > maxSum && nums[i] + nums[j] + nums[k] <= maxNum){
maxSum = nums[i] + nums[j] + nums[k];
}
}
}
}
System.out.println(maxSum);
}
}
다중 중첩 반복문이지만 조건문만 제거해도 훨씬 가독성이 좋은 것 같다.
하지만 백준에 코드를 제출했을 때, 1차 코드와 비교해서 2차 코드의 성능이 유의미하게 올라가진 않았다.
3차 코드
import java.io.*;
import java.util.StringTokenizer;
public class Main {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
String[] input = br.readLine().split(" ");
int count = Integer.parseInt(input[0]);
int maxNum = Integer.parseInt(input[1]);
int[] nums = new int[count];
int maxSum = 0;
StringTokenizer st = new StringTokenizer(br.readLine());
for (int i = 0; i < count; i++) {
nums[i] = Integer.parseInt(st.nextToken());
}
for (int i = 0; i < nums.length; i++) {
for (int j = i + 1; j < nums.length; j++) {
for (int k = j + 1; k < nums.length; k++) {
if(nums[i] + nums[j] + nums[k] > maxSum && nums[i] + nums[j] + nums[k] <= maxNum){
maxSum = nums[i] + nums[j] + nums[k];
}
}
}
}
bw.write(maxSum+"");
bw.flush();
bw.close();
br.close();
}
}
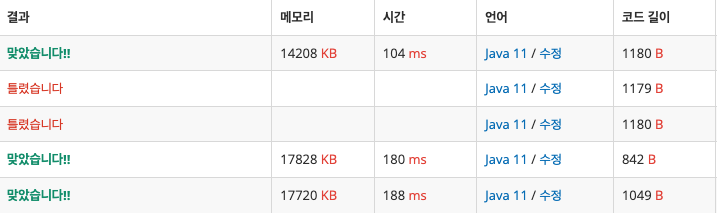
스캐너 대신 버퍼를 사용해서 입출력을 해보았다.
코드를 작성할 때는 배열에 split한 값을 담고, 문자열을 정수로 변환하는 과정이 필요해서 번거롭지만,
제출해보면 성능은 개선되는 것을 볼 수 있다.
Scanner는 내부에서 정규 표현식으로 한 글자씩 입력을 분석하고 원하는 타입으로 변환 후 반환한다.
BufferedReader는 버퍼를 이용해서 한 줄 단위로 한꺼번에 읽어서 반환한다. (필요 시 개발자가 타입 변환)
=> 정규 표현식을 사용해서 값을 변환하지 않고, 한 번에 여러 글자를 읽어오는 BufferedReader가 훨씬 빠르다.
System.out.println()은 출력할 때마다 출력 스트림으로 데이터를 보낸다.
BufferedWriter는 버퍼를 이용해서, 버퍼가 꽉 차거나 flush()가 호출될 때 한꺼번에 데이터를 출력한다.
=> 자주 출력하는 상황에서는 BufferedWriter가 훨씬 빠르다.
'알고리즘 > 문제 풀이' 카테고리의 다른 글
| [백준][Java] 주어진 단어에서 가장 많이 사용된 알파벳 출력 (0) | 2025.03.27 |
|---|---|
| [프로그래머스][Java] 자연수 뒤집어 배열 만들기 (0) | 2025.03.17 |
| [백준][Java] EOF(End of File) 처리하기 (0) | 2025.03.14 |
| [백준][Java] 0 0이 입력될 때까지 연산 (0) | 2025.03.14 |
| [Java, Python] 배열의 평균값 (0) | 2025.03.06 |