DB(H2) 사용 방식 / 드라이버와 dialect의 역할과 차이점 / 자바의 데이터 접근 기술 분류
DB 사용 방식
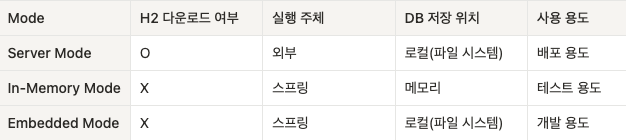
1. Server Mode
- 컴퓨터에 DB 엔진을 설치해서 사용하는 방식
- 애플리케이션과 DB과 분리되어 있기 때문에 여러 애플리케이션이 동일한 DB 사용하기에 적합
- 배포 시에 사용
2. In-memory Mode
- 애플리케이션에 DB 엔진이 내장되어 있어, 애플리케이션과 함께 실행되고 종료되는 방식
- 애플리케이션이 종료되면 데이터가 휘발됨
- 단위 테스트 시에 사용
ex. h2
# application.properties
spring.datasource.driver-class-name=org.h2.Driver
spring.datasource.url=jdbc:h2:mem:{DB 이름} //mem이 있으면 인메모리 방식
spring.datasource.username=sa
spring.datasource.password=
h2.console.enabled=true //h2-console 사용 여부
h2.console.path= /h2-console //localhost:8080/h2-console을 입력하면 브라우저로 DB 콘솔 사용 가능
DB_CLOSE_DELAY=-1 //을 url 제일 뒤에 추가하면 앱이 실행되는 동안 DB가 계속 열려있음
DB_CLOSE_ON_EXIT=FALSE //을 url 제일 뒤에 추가하면 앱이 종료될 때 DB의 자동 종료 방지
//=> h2-console에서 DB 조회를 하고 싶을 때 사용
3. Embedded Mode
- In-memory 모드와 동일하게 애플리케이션과 함께 실행되고 종료되는 방식
- 데이터를 로컬에 저장하기 때문에 애플리케이션을 종료해도 데이터가 휘발되지 않음
# application.properties
spring.datasource.driver-class-name=org.h2.Driver
spring.datasource.url=jdbc:h2:{DB가 저장될 경로}
spring.datasource.username=sa
spring.datasource.password=
JDBC 드라이버의 역할
데이터베이스 드라이버는 애플리케이션과 데이터베이스 간의 통신을 중개하는 역할
다양한 데이터베이스 시스템(Oracle, MySQL, PostgreSQL)마다 호환되는 드라이버가 있다.

드라이버와 dialect의 차이점
dialect는 여러 DBMS가 애플리케이션과 호환될 수 있도록 변환해주는 역할을 한다고 했는데, 드라이버와 어떤 차이점이 있을까
드라이버의 주요 역할
- DB 연결 및 종료
- 쿼리 실행(excute), 결과 수신
- 자바 코드로 작성한 SQL을 DBMS가 이해할 수 있도록 변환하여 전달
- 데이터 타입 변환(VARCHAR <-> String, TIMESTAMP <-> LocalDateTime)
=> JDBC 드라이버는 물리적 통신과 데이터 전송/변환 담당
Dialect의 주요 역할
- DBMS별 SQL 문법 차이 처리(LIMIT/OFFSET, AUTO_INCREMENT, SEQUENCE, BOOLEAN)
- DB에 맞게 DDL 생성
- NOW(), SYSDATE 등 DB마다 다른 내장 함수 처리
=> Dialect는 SQL 문법 차이를 흡수하고, ORM이 DB 독립적으로 동작하도록 도움
결론적으로, 데이터 변환을 한다고 했을 때
타입 변환은 JDBC 드라이버가 처리하고, 문법/형식 변환은 Dialect가 처리한다.
JDBC Driver Manager의 런타임 시점 흐름도
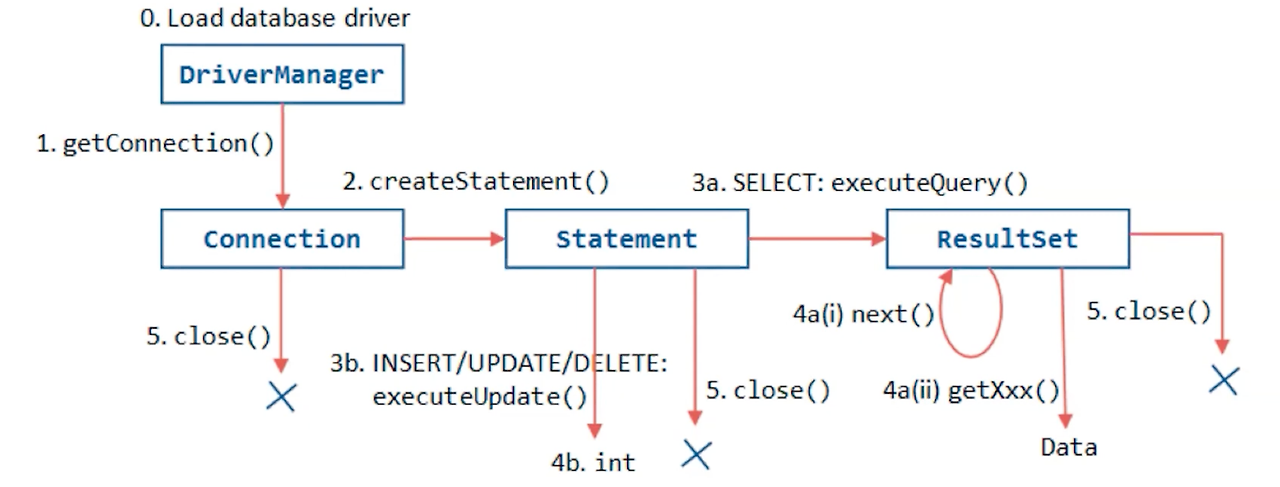
Connection : 쿼리 요청을 위한 연결 생성
Statement : 쿼리 요청 가능한 상태로 변경
ResultSet : 쿼리 결과를 응답
JDBC / JDBC Template / MyBatis / ORM
1. JDBC (Java Database Connectivity) — 가장 원시적인 방식
- 모든 DB 처리 코드 수동 작성
- 자원 연결/해제, SQL 실행, 결과 매핑 모두 직접 수행해야 함
- 코드가 길고 복잡함
Connection conn = DriverManager.getConnection(DB_URL, USER, PASS);
PreparedStatement stmt = conn.prepareStatement("SELECT * FROM users WHERE id = ?");
stmt.setLong(1, id);
ResultSet rs = stmt.executeQuery();
User user = null;
if (rs.next()) {
user = new User();
user.setId(rs.getLong("id"));
user.setName(rs.getString("name"));
}
rs.close();
stmt.close();
conn.close();
2. JdbcTemplate — JDBC 반복 코드 추상화
- 자원 처리 자동화 (Connection, PreparedStatement, ResultSet 정리)
- 결과 매핑은 RowMapper로 개발자가 작성해야 함
- JDBC 보일러플레이트 제거만 해줌
public class UserRowMapper implements RowMapper<User> {
public User mapRow(ResultSet rs, int rowNum) throws SQLException {
User user = new User();
user.setId(rs.getLong("id"));
user.setName(rs.getString("name"));
return user;
}
}User user = jdbcTemplate.queryForObject(
"SELECT * FROM users WHERE id = ?",
new Object[]{id},
new UserRowMapper()
);3. MyBatis — SQL Mapper 프레임워크
- JDBC 기반 SQL Mapper 프레임워크로, 객체 매핑과 JDBC 반복 코드 자동화
- SQL은 직접 작성 (자동화하되, SQL문은 직접 작성하고 싶을 때 사용)
실행 흐름
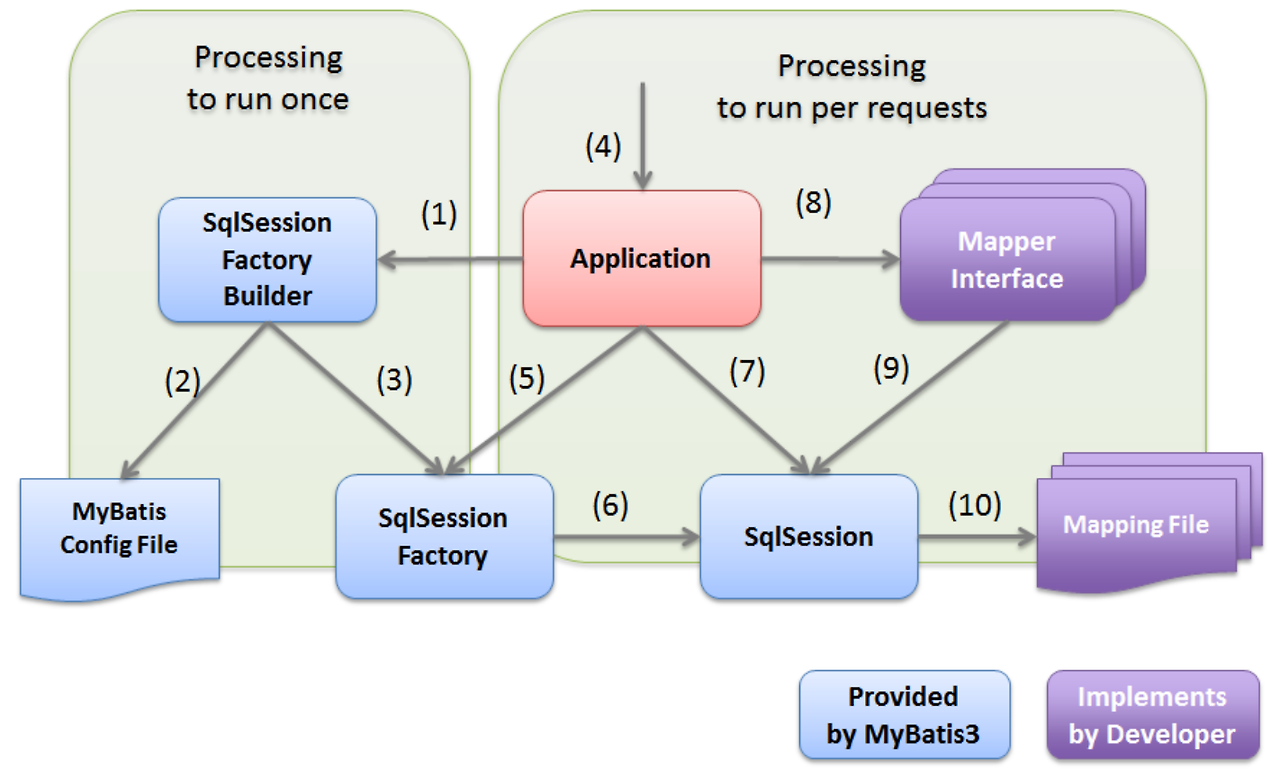
| 단계 | 구성요소 | 설명 |
| 1 | SqlSessionFactoryBuilder | mybatis-config.xml을 읽고 SqlSessionFactory 생성 |
| 2 | mybatis-config.xml | Type Alias, Mapper XML의 위치 설정 |
| 3 | SqlSessionFactory | SqlSession을 생성하는 팩토리 객체 |
| 4 | SqlSession | SQL을 실행할 수 있는 세션 객체 |
| 5 | Mapper 인터페이스 | SQL과 매핑되는 Java 인터페이스 |
| 6 | Mapper XML | SQL 정의 및 결과 매핑 파일 (UserMapper.xml) |
// 2단계 : /resources/mybatis-config.xml
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<typeAliases>
<package name="com.thesun4sky.querymapper.domain"/>
</typeAliases>
<mappers>
<mapper resource="mapper/UserMapper.xml"/>
</mappers>
</configuration>두 가지 Mapper 사용 방식
방법 1: DAO + SqlSession 직접 사용
// Mapper Interface 대신 Dao 클래스 정의
@Component
public class UserDao {
private final SqlSession sqlSession;
public UserDao(SqlSession sqlSession) {
this.sqlSession = sqlSession;
}
public User selectUserById(long id) {
return this.sqlSession.selectOne("selectUserById", id);
}
}// Mapper XML
<mapper namespace="UserDao">
<select id="selectUserById" resultType="User">
SELECT id, name FROM users WHERE id = #{id}
</select>
</mapper>
방법 2: Mapper 인터페이스 사용
// Mapper Interface 정의
@Mapper
public interface UserMapper {
User selectUserById(@Param("id") Long id);
}<mapper namespace="com.example.mapper.UserMapper">
<select id="selectUserById" resultType="User">
SELECT id, name FROM users WHERE id = #{id}
</select>
</mapper>https://teamsparta.notion.site/3-RawJPA-49768671cced4fdd8a03cd72f55c41f1
4. ORM (JPA / Hibernate 등) — 완전 객체 중심 설계
- SQL 작성 없이 객체만 정의하면 SQL 자동 생성
- DB와 객체 간 상태 동기화
- 복잡한 쿼리에는 JPQL 또는 NativeQuery 사용 가능
@Entity
public class User {
@Id @GeneratedValue
private Long id;
private String name;
}
public interface UserRepository extends JpaRepository<User, Long> {
Optional<User> findById(Long id); // 쿼리 자동 생성
}// 호출 코드
User user = userRepository.findById(1L).orElse(null);